Naive Bayes classifier
나이브 베이즈 분류기의 경우 간단하지만 널리 쓰이는 probabilistic 방식으로 attribute가 주어졌을 때 어떠한 클래스에 속할 확률을 제공합니다. 즉 클래스 예측 뿐 아니라 클래스에 속할 확률까지 알려주는 알고리즘입니다.
나이브 베이지 분류기는 P(Class label = Purchase | Salary = 5000, Age = 25, Gender = "Male") =? 와 같은 질문에 답을 제공합니다. 월급은 5000, 나이는 25, 성별은 남성일 때 Purchase 클래스에 속할 확률은 얼마인가?
결합 확률 P(x, y)란 x와 y가 동시에 발생할 확률을 의미하며, 조건부 확률 P(y | x)는 x가 발생했을 때 y가 발생할 확률을 의미합니다.
우리는 조건부확률을 일반적으로 다음과 같은 식으로 표현할 수 있습니다. 조건부 확률 P(y | x)는 x가 발생했을 때 y가 발생할 확률을 알고 싶다면, y가 발생했을 때 x가 발생할 확률인 P(x | y)를 통해 유추 가능합니다.

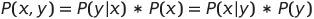
↓
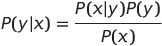
즉, 우리는 x는 데이터, y는 클래스 레이블이라고 한다면 P(y|x)는 데이터 x가 y 클래스에 속할 확률을 구하는 것이고, 이는 클래스가 y일 때 x1, x2, ... xd가 몇번 등장하는가를 통해 유추할 수 있습니다. 여기서 P(y | x1, x2, ... , xd)를 사후확률, P(y)를 사전확률이라고 합니다.

앞서, P(Salary = 5000, Age = 25, Gender = "Male") 라는 예시에서 각 attribute 전체가 매칭되는 것은 어려울 것입니다. 즉, 봉급은 5000 이며 나이는 25살이며 성별은 남성인 attribute가 동시에 만족되는 경우는 거의 업어서 그 값이 0에 가까워질 것입니다. 그렇기 때문에 나이브 베이즈는 클래스 조건부 독립성(class conditional independence)을 가정합니다. 즉 P(x1, x2, ... , xd | y)를 P(x1 | y), P(x2 | y), ... ,P(xd | y)로 분리하여 계산할 수 있게 됩니다.
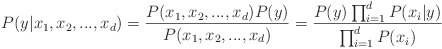
위의 식에서 분모 값은 y값과 상관없이 동일한 값을 가지기 때문에 구할 필요가 없게 됩니다. 결국 결론적으로 다음과 같은 식으로 설명할 수 있습니다.

'Data Mining' 카테고리의 다른 글
| K-Nearest Neighbor Algorithm (KNN 알고리즘) (0) | 2022.01.02 |
|---|---|
| Hadoop Installation on Ubuntu (나의 하둡 설치 삽질기) (5) | 2021.12.20 |
| Cloud Computing (0) | 2021.11.25 |
| CURE Algorithm (Clustering Using REpresentatives) (0) | 2021.11.22 |
| BFR Algorithm (0) | 2021.11.22 |




댓글