Reference book으로 Jure Leskovec의 Mining of Massive Datasets을 사용하였으며,
글에 오류가 있을 경우 계속하여 수정할 예정입니다 :)

What is Data Mining ?
“data mining” is the discovery of “models” for data.
통상적으로 데이터 마이닝의 정의는 '데이터에 맞는 model을 찾는 것'이다.
(model은 다양하기 때문에 여기서는 설명하지 않을 것임)
Data Mining Tasks
Data mining task는 두가지로 분류할 수 있다.
1) Descriptive methods : 데이터를 잘 묘사하는 패턴을 찾는 방법 (ex. clusterting)
2) Predictive methods : unknown하거나 future value들을 예측하는 방법 (ex. Recommender systems)
예를 들어, Customer churn 문제에 대해 회사A를 떠나 회사B로 떠날 확률을 얼마인지 예측하는 것이라면 predictive method, 회사A를 떠나 회사B로 떠난 사람의 특징(나이, 성별, 수입 등..)을 묘사하는 것이라면 descriptive method가 될 것이다.
Meaningfulness of Analytic Answers
데이터 마이닝의 위험은 의미없는 패턴을 발견하는 것인데,
데이터 마이닝을 통해 얻어낸 패턴의 경우의 수 < 랜덤하게 뽑아낸 패턴의 경우의 수 라면
그 패턴은 쓸모없는 패턴이라는 것이다.
이를 본페르니의 원칙 (Bonferroni's principle)이라 한다.
* Assumption
1. 10억 명(10^9)의 사람이 존재한다
2. 모든 사람들은 100일에 한 번꼴로 호텔에서 시간을 보낸다
3. 호텔에는 100명의 사람을 수용한다
4. 호텔은 10000개(10^5)가 존재한다
5. 1000일 동안 호텔 기록들을 examine한다
* example
2명의 사람이 호텔에 갈 확률
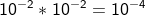
2명의 사람이 같은 호텔을 선택할 확률
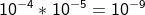
2명의 사람이 같은 호텔을 선택할 확률이 서로 다른 두 날에 똑같이 일어날 확률
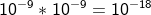
가능한 사람 쌍의 수
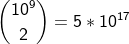
가능한 날짜 쌍의 수
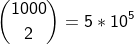
결국, evil-doers의 수는 25만 쌍이 나오는데, 이는 random 추출한 것이다.
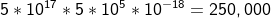
실제로 10쌍의 악당이 있다고 가정하면 evil-doers를 찾기 위해 다른 25만 쌍을 조사해야 하므로 이러한 방식은 실현가능하지 않다.
'Data Mining' 카테고리의 다른 글
| Flajolet-Martin Algorithm (0) | 2021.11.10 |
|---|---|
| Bloom filters (0) | 2021.11.06 |
| DGIM Algoritm (0) | 2021.11.04 |
| Data Streams (0) | 2021.11.03 |
| MapReduce (0) | 2021.11.03 |




댓글