Wear Leveling

플래시 메모리는 "P/E 주기"라고 하는 Program/Erase 주기의 제한이 있습니다. 플래시 메모리 특성상 write을 하기 위해서는 반드시 erase를 수반하기 때문에 특정 블록에 반복적으로 overwrite을 하게 되면 메모리의 수명이 감소하게 됩니다. 그래서 SSD의 모든 블록에 write을 고르게 분산하여 고르게 마모되도록 하는 것이 Wear leveling입니다.

(a) disk write pattern을 보면 디스크의 일부분에서만 write가 일어나는 것을 볼 수 있습니다. spatial locality의 특성상 write가 일어나는 주변에서 계속해서 write이 일어나기 때문에 physical block의 약 40%에서는 erase가 일어나지 않습니다. 그렇기 때문에 erase operation을 균일하게 분산하여 메모리 수명을 증가시키는 것이 필요합니다.
* ideal wear leveling

(a)의 경우 wear leveling을 전혀 고려하지 않기 대문에 block 5,6,9,10에만 erase 작업이 균일하지 않게 수행됩니다.
반면, (b)는 '균일하다'는 관점에서는 좋은 케이스가 될 수 있습니다. 하지만 이 경우에 erase count를 균일하게 만들기 위해 cold data를 hot block으로 옮기는 상황에서 이미 hot block안에 존재하는 많은 데이터를 다른 block에 백업해두고 erase를 해야 cold data를 hot block으로 이동할 수 있습니다. 또한 cold block에 write하기 위해서는 free block으로 만들어야 하는데 이때 erase 작업을 요구하게 됩니다. 이러한 경우에는 erase count가 균등해지긴 하나 erase count를 오히려 증가시키게 되고, count를 줄이는 (c)와 같은 상황을 이상적은 wear leveling이라고 할 수 있습니다.
Type of Wear leveling
Wear leveling은 어떠한 데이터를 wear leveling할 것인가에 따라 Dynamic wear leveling과 Static wear leveling으로 구분됩니다. Wear leveling의 데이터는 보통 static data와 dynamic data가 존재합니다. Static data는 OS나 응용소프트웨어처럼 변화가 잘 일어나지 않는 데이터로 일종의 cold data라고 생각하면 됩니다. 반면 Dynamic data는 rewrite, 즉 업데이트가 자주 일어나는 데이터로 user data가 있습니다. 결국 Dynamic wear leveling는 dynamic data만 wear leveling의 고려 대상으로 삼는 것이며, Static wear leveling은 static data 뿐 아니라 dynamic data 둘 모두를 wear leveling의 대상으로 합니다.
Dynamic Wear Leveling
Dynamic wear leveling는 데이터 블록에 write 또는 erase 명령이 내려올 때만 수행되며, erase count가 적은 블록이 향후 쓰기 작업에 우선적으로 사용되도록 합니다. 그렇기 때문에 static(or cold)한 데이터는 wear leeling이 적용되지 않으며, 그 데이터는 다른 블록으로 이동하지 않게 됩니다.
* Cost-Age-Time (CAT)
Dynamic wear leveling의 한 종류로 Cost-Age-Time policy가 있습니다. CAT은 wear leveling과 garbage collection 모두를 고려한 알고리즘으로 (Cost * Time ) / Benefit (아래의 식)을 최소화하는 block을 victim으로 선정합니다.

이 식을 최소화 하기 위해서는 아래와 같은 블록을 선택해야 합니다.
1) EC가 적은 블록
2) u/(1-u)를 최소화하는 블록
: u는 block utilization으로 valid pages / total pages로 나타낼 수 있습니다. u / 1- u는 결국 valid page가 많을수록 증가하게 됩니다. 하지만 우리는 위와 같은 공식을 최소화해야 하므로 invalid가 많은, 즉 valid data가 적은 블록을 선택해야 합니다.
3) Age가 큰 블록
: Age = F(the current time - the most recent modified time)으로 현재 - 가장 최근 update 된 시점으로 나타낼 수 있습니다. 그러므로 Age가 큰 블록을 선택하기 위해서는 update가 오랫동안 되지 않은 block을 선택하면 됩니다. 여기서 F는 age값이 커짐에 따라 공식에 미치는 영향력을 normalize하기 위해서 적용하는 Tranformation Function이라고 생각하시면 됩니다 (u/1-u는 rate의 개념이므로 그 값이 크지 않음).
Static Wear Leveling
Static wear leveling은 dynamic 뿐 아니라 staticdata에도 wear leveling이 수행됩니다. 기본적으로 dynamic WL처럼 작동하나 block의 erase count가 특정 임계값을 넘어서게 되면 static data block을 이동시켜 상대적으로 erase count가 적은 블록이 우선적으로 사용되도록 합니다.
* Hot Cold Swapping

hot-cold swapping은 oldest블록에는 hot데이터가 youngest블록에는 cold 데이터가 있다는 전제하에, oldest블록과 youngest블록을 희생 블록으로 고른 후 블록 내에 존재하는 데이터를 교환합니다. oldest블록에는 cold한 데이터를 옮겨지기 때문에 오래 동안 삭제가 일어나지 않게 되어 더 이상 erase count가 증가하지 않도록 방지합니다. 또한 youngest블록에는 hot한 데이터가 옮겨짐으로써 잦은 update로 인하여 삭제 횟수가 증가하게 되어 블록 간의 wearleveling이 이루어지게 됩니다.
그러나 hot-cold swapping은 한 번 oldest 했던 블록이, 다음 wear leveling이 진행될 때에도 여전히 oldest하여, 계속해서 희생 블록으로 선택되는 가능성이 높으므로 계속해서 swapping이 일어날 수 있어 oldest 블록의 erase count가 증가한다는 단점을 가집니다.
* Dual Pool Algorithm
Dual Pool 알고리즘은 hot-cold swapping의 단점을 해결한 알고리즘입니다. hot-cold swapping이 특정 블록만 계속해서 victim으로 선택되어 erase count가 급격하게 증가하는 것을 막기 위해 hot pool과 cold pool을 두어 관리합니다. hot pool은 업데이트가 자주 일어나는 블록들의 모음이고 cold pool은 업데이트가 자주 일어나지 않는 블록의 모음입니다. dual- pool 알고리즘은 cold-datamigration,cold pool adjustment, hot pool adjustment을 통해 wearleveling합니다.
1) cold-data migration
: cold-data migration은 erase가 일어날 때 hot pool의 oldest block의 삭제 횟수와 cold pool의 youngest block의 삭제 횟수의 차이가 특정 임계값보다 커지는 조건이 만족되면 수행됩니다. cold-data migration의 과정은 다음과 같습니다.
1. hot pool의 max EC와 cold pool의 min EC를 구하여 차이를 구한다.
2. 그 차이가 임계값보다 크면 hot pool의 oldest block의 valid page를 다른 블록에 copy한 후 oldest block은 삭제한다.
3. cold pool의 youngest block의 valid page를 hot pool의 oldest block에 copy한 후 youngest block을 삭제한다.

dual-pool은 hot-cold swapping의 단점인 특정 블록이 victim block으로 선정되는 것을 막기 위해 블록의 pool을 계속해서 바꿔주는데, oldest block이 cold data를 받았으면 cold pool의 EC가 가장 높은 곳으로 옮기고 cold pool의 youngest는 hot pool의 EC가 제일 높은 곳으로 이동시킴으로써 oldest와 youngest만이 계속해서 swapping이 일어나는 것을 방지합니다.
2) Adaptive Pool Resizing
hot pool의 oldest가 cold data가 되고 cold pool의 youngest가 hot data가 되는 dynamic한 변화가 발생하는 경우가 있습니다. 즉, 2가지의 케이스로 요약 가능합니다.
Case 1 ) Cold Pool의 cold data가 hot data가 되면 cold pool adjustment를 수행
Case 2 ) Hot Pool의 hot data가 cold data가 되면 Hot pool adustment를 수행
① cold pool adjustment
cold pool adujstment의 기본 아이디어는 갑자기 erase가 빈번하게 일어나는 block을 hot pool로 옮기는 것입니다. hot pool로 이동하기 위해서는 ' cold pool의 MAX ECC를 가진 블록 - hot pool의 MIN ECC를 가진 블록 '이 임계치를 넘어야 합니다.
여기서 EEC는 Effective Erasure Cycle로, cold pool migration이 일어난 이후로부터 발생한 erase count를 의미합니다. EEC는 hot pool의 oldest block을 cold pool로 옮겼을 때 0으로 리셋되기 때문에 △EEC는 블록의 hot함의 척도로 사용됩니다. 예시를 통해 cold pool adjustment를 살펴보겠습니다.
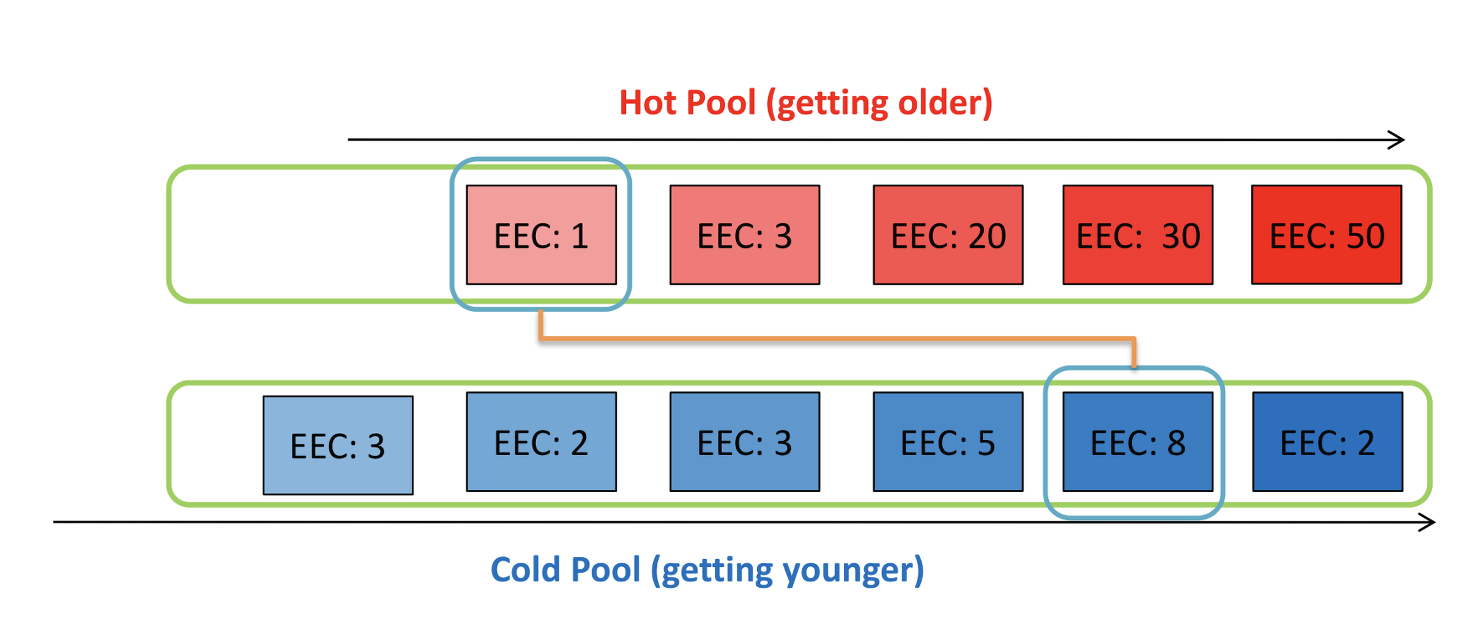

cold pool adjustment의 임계치를 4라고 가정한다면, hot pool에서 EEC가 1인 블록과 cold pool에서 EEC가 8인 블록의 차가 7이기 때문에 cold pool의 block을 hot pool로 이동시킵니다.
② hot pool adjustment
hot pool adjustment는 hot pool의 hot data를 cold pool로 옮기는 것입니다. hot pool adjustment도 cold pool adjustment와 마찬가지로 특정 조건을 만족해야 합니다. 즉, hot pool adjustment는 hot pool의 oldest block의 EC - hot pool의 youngest block의 EC가 임계치의 2배를 넘으면 수행됩니다.
여기서 왜 임계치의 2배를 넘어야 수행되는지 의문이 생기게 되는데, 이는 cold migration이 일어나게 되면 hot pool내의 oldest block과 youngest block은 이미 threshold를 넘는 상태이기 때문에 이 상태에서 hot pool adjustment를 수행하면 oldest와 youngest가 계속적으로 swapping이 일어나기 때문입니다. 예시를 통해 hot pool adjustment를 살펴보겠습니다.

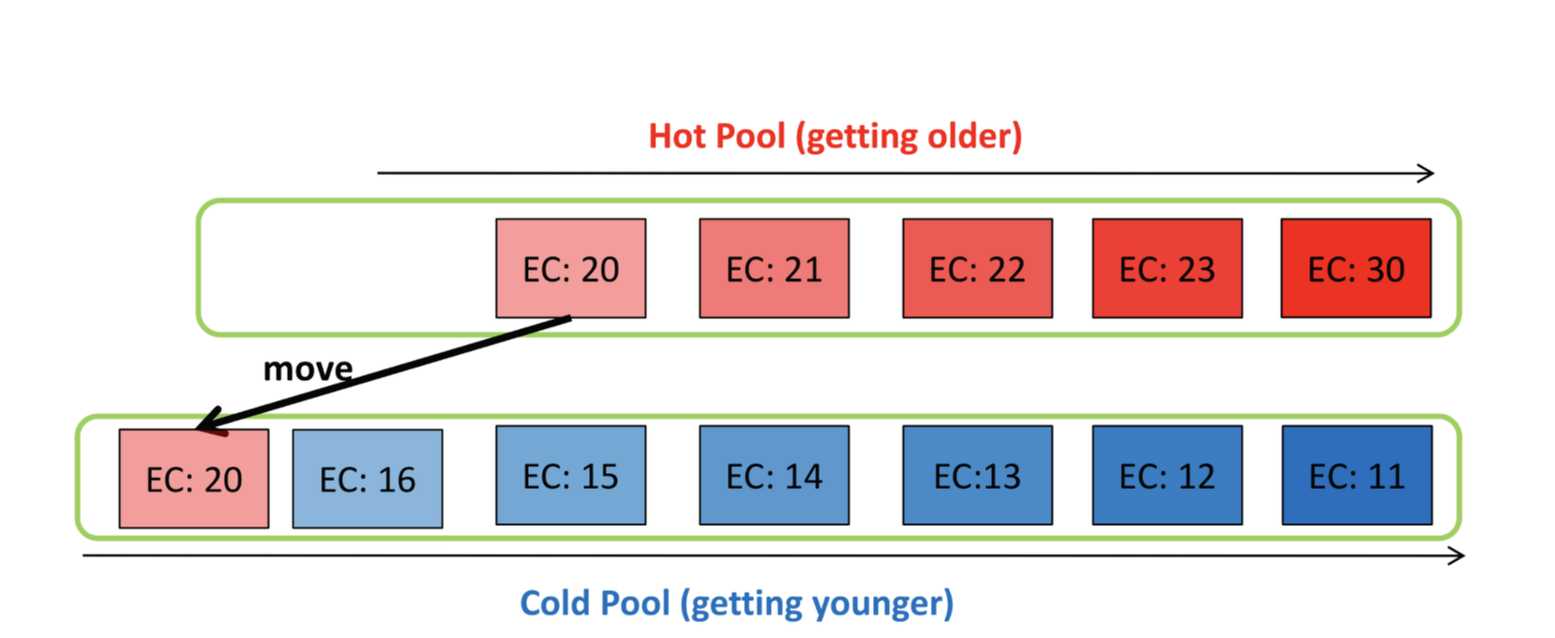
hot pool adjustment의 임계치를 4라고 가정한다면, hot pool에서 EC가 가장 높은 블록과 EC가 가장 낮은 블록의 차는 10이 되고 이는 임계치의 두배인 8보다 크므로 hot block의 youngest block을 cold pool로 이동시킵니다.
'Storage' 카테고리의 다른 글
| DFTL (Demand-based FTL) (4) | 2022.04.10 |
|---|---|
| [FTL] BAST, FAST (0) | 2022.01.10 |
| FTL (0) | 2022.01.09 |
| Data Deduplication (0) | 2021.12.21 |




댓글