Data Deduplication
Deduplication이란 스토리지 효율의 향상을 위해 서로 다른 데이터 청크 간의 중복된 데이터를 제거하는 작업을 말합니다.
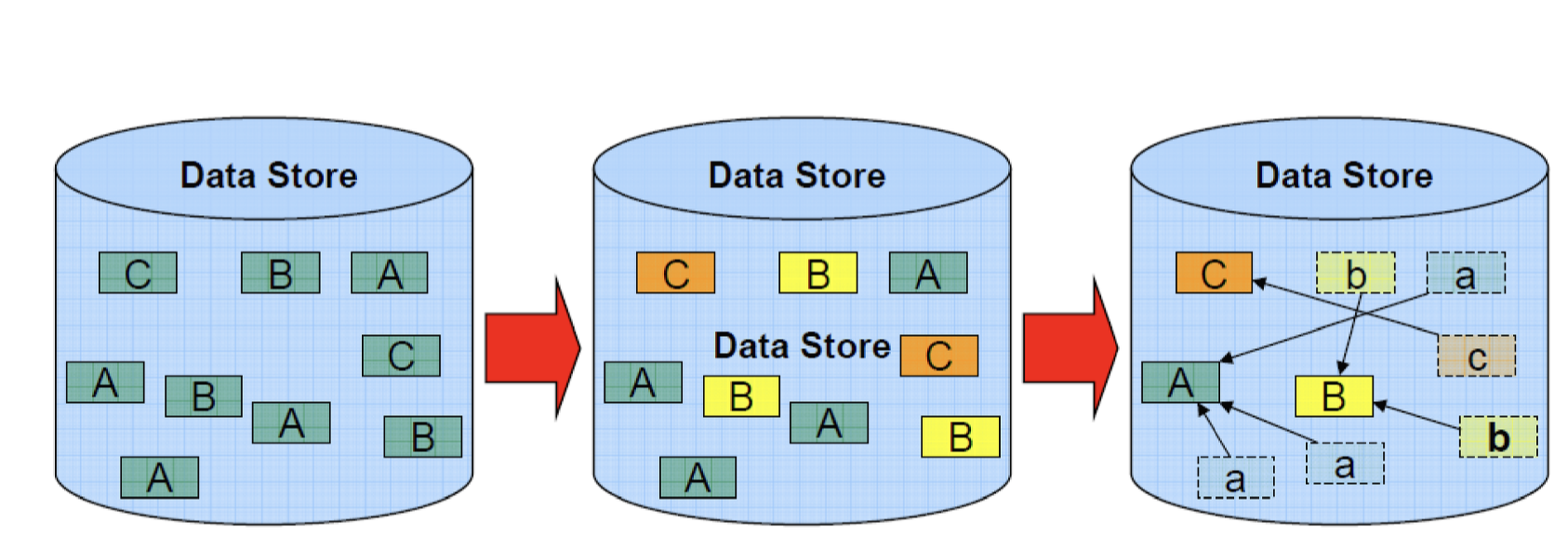
Deduplication의 과정은 먼저 데이터를 청크 단위로 쪼갠 후 해쉬함수를 적용하여 특정 해쉬값을 만들어 냅니다. 해쉬를 했기 때문에 중복 데이터는 동일한 해쉬값을 가지고 있을 것이므로 해쉬값을 비교하여 중복 데이터를 찾아나갑니다. 이때 중복된 데이터 청크들은 포인터로 대체하고 삭제합니다.
Data Chunking Methods
데이터를 청크 단위로 쪼개는 4가지 방법
1 ) Whole file chunking
whole file chunking은 각각의 파일을 하나의 청크로 간주합니다. 이 방식은 오버헤드는 적으나, 파일 자체가 청크이기 때문에 하위 파일의 수준에서는 중복데이터를 발견할 수 없다는 단점을 가집니다.
2) Fixed-size chunking
데이터를 고정된 청크 사이즈로 자르기 때문에 하위 파일의 수준에서도 중복 데이터를 발견할 수 있습니다. 하지만 삽입과 삭제로 데이터의 이동이 일어나 offset이 변경되게 되면 고정된 사이즈로 청크를 잘랐기 떄문에 거의 중복된 데이터임에도 불구하고 중복을 발견할 수 없게 됩니다.
3) Variable-size chunking
가변 크기로 청크를 자르는 방식은 롤링 해쉬 알고리즘을 사용하여 평균적인 청크 사이즈를 결정합니다. 롤링 해쉬 알고리즘은 sliding window같이 문자열을 훑어가며 해쉬값을 구하는데 유용한데, 중복되는 부분의 해쉬값은 제외하고 업데이트되는 부분만 해쉬값을 계산하여 중복되는 연산을 줄여줍니다. overlapped chunking을 하는 방식이기 때문에 고정 사이즈로 청킹하는 방식에서 가졌던 offset문제를 해결할 수 있습니다.
4) Format-aware chunking
format-aware chunking은 가변사이즈 청킹 방식에 더하여 데이터의 포멧이나 구조까지 고려하는 알고리즘으로, 데이터 중복을 가장 많이 줄일 수 있지만 오버헤드가 크다는 단점을 가집니다.
Dedup benefits and drawbacks
benefits
- 중복된 데이터를 제거하므로 디스크 공간을 절약하고, 네트워크 사용량 감소로 인한 회선 비용 절감 효과도 누릴 수 있음
- 중복된 데이터의 write 성능이 향상 (중복을 제거하고 write하므로 throughput이 증가하므로)
- 백업의 경우 각각 다른 버전의 백업 데이터 대부분이 실제로는 중복을 매우 많이 포함하기 때문에 효율성이 향상됨
drawbacks
- 중복 데이터는 하나의 share copy빼고 나머지 데이터는 삭제 후 포인터만 남기기 때문에 중복떼이터를 read할 때 포인터를 다 따라가서 일일히 데이터를 찾고 복구 후에 그 데이터를 읽을 수 있기 때문에 read성능이 좋지 않음
- 위와 같은 이유로 실제 데이터를 가지고 있는 share copy가 삭제되면 모든 데이터의 손실이 발생함
- CPU, 메모리 등을 많이 사용하게 됨
- Dedupe의 경우표준화된 기술이 없고 회사마다 다른 기술을 사용하기 때문에 호환이 불가능한 문제 발생 (vendor lock-in)
False Matches ?
false match란 서로 다른 데이터 청크가 같은 해쉬값을 가지는 것입니다. 중복된 데이터는 같은 해시값을 가지게 되는데, 다른 데이터임에도 같은 해시값을 가지게 되는 경우가 됩니다. 이런 경우에 서로 다른 데이터임에도 불구하고 해시값이 같기 때문에 중복데이터로 간주하고 데이터를 버리게 되고, 데이터를 read할 때 모든 포인터를 읽어 복원할 때 잘못된 데이터를 가져오게 됩니다. 이러한 데이터 손실을 피하기 위해서는 몇가지 방법이 존재합니다. 하지만 이러한 방식은 성능을 향상시키지만 computation을 위한 리소스 사용이 증가하게 됩니다.
1) long signature을 만드는 해쉬 함수를 사용
2) 여러 개의 해시 함수를 사용
3) 청크가 가지고 있는 정보를 활용해 identifier을 만듦
4) byte단위로 청크를 비교한다.
A Typical Dedupe System Architecture
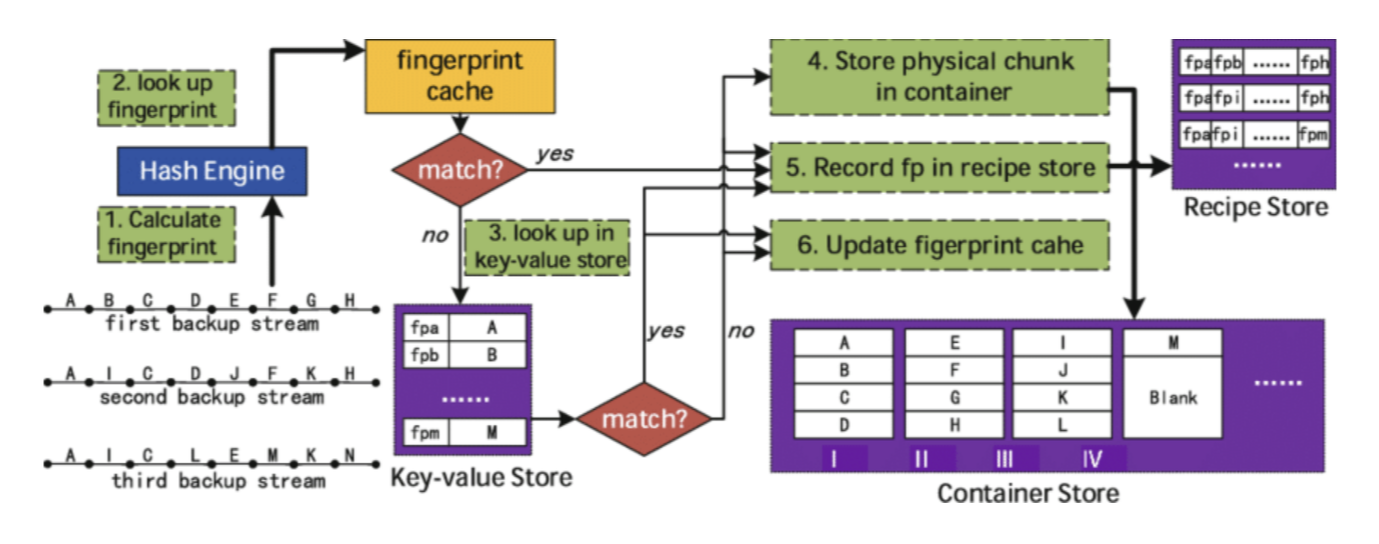
그림을 보면 복잡해 보이는데 간단히 설명해보도록 하겠습니다!
먼저, 데이터를 청킹한 이후 청크 당 fingerprint를 계산합니다. 이때 자주 액세스되는 fingerprint는 Dram에 캐싱합니다. Dram의 cache를 체크하여 매칭이 발생하면 fingerprint를 recipe store에 저장하고, 그렇지 않으면 KVS(Key-Value Store)로 이동합니다. KVS에서 cache를 체크하여 매칭이 발생하면 fingerprint를 recipe store에 저장합니다. KVS에서 매칭이 되지 않으면 container sotre에 실제 데이터 청크를 쓰고, KVS에는 index를 업데이트하고 recipe store에 fingerprint를 씁니다. (-> unique data)
Where dedupe is Performed
Deduplication은 '어디에서' 수행되느냐에 따라 Source-side(client-side)와 Target-side(sever-side)로 분류됩니다.
Source-Side
- 스토리지에 데이터를 넣기 전에 클라이언트가 dedupe을 수행하는 방식
- dedup을 한 이후에 스토리지에 넣으므로 network bandwith를 보존할 수 있음
- 클라이언트가 데이터의 포맷을 더 잘 알기 때문에 dedup이 더 효과적
- 클라이언트의 리소스를 많이 사용하며, 클라이언트가 디바이스나 소프트웨어를 보유하고 있어야 함.
- 스푸핑같은 보안 문제가 발생할 수있따.
Target-Side
- 스토리지 서버에서 dedupe을 수행
- 클라이언트가 직접 소프트웨어나 디바이스를 가질 필요가 없으나, 서버의 리소스를 많이 사용하게 됨
- 전체 클라이언트들을 대상으로 중복을 직접적으로 비교할 수 있음
When dedupe is Performed
Deduplication은 '언제' 수행되느냐에 따라 In-band와 Out-of-band로 분류됩니다.
In-band
- 클라이언트가 서버로 데이터를 보내는 과정에서 dedupe 수행
- 데이터를 dedupe한 후 서버에 저장하므로 스토리지 용량 절약이 가능하고 후처리가 필요 없음
- 데이터를 가져올 때 bottleneck발생이 가능하고, 각 I/O stream에서 하나의 dedup만 실행 가능하다
- 기존 서버에 저장된 데이터와 중복 비교를 할 수 없다
Out-of-band
- 서버에 데이터를 다 쓴 이후에 dedup을 수행
- 기존 서버에 저장된 데이터와 dedup 수행이 가능하다.
- 동시에 병렬적으로 deudp 수행이 가능하다.
- 서버에 저장하는 오버헤드와 dedup 오버헤드 둘다 발생한다
- dedup을 하기 위한 스토리지 용량 뿐 아니라 실제 데이터를 저장할 용량 또한 필요하다.
'Storage' 카테고리의 다른 글
| DFTL (Demand-based FTL) (0) | 2022.04.10 |
|---|---|
| [FTL] BAST, FAST (0) | 2022.01.10 |
| FTL (0) | 2022.01.09 |
| Wear Leveling (WL) (0) | 2021.11.27 |




댓글