Intro
FTL의 mapping scheme 중에서는 page-level mapping, block-level mapping, hybrid-level mapping이 존재합니다. page-level mapping과 block-level mapping을 설명하였으니 앞선 포스팅을 참고하시길 바랍니다!
FTL
FTL FTL이란 Flash Translation Layer의 약자로, 플래시 메모리의 특성을 감추면서 하드디스크의 기능처럼 수행할 수 있도록하는 소프트웨어층을 의미합니다. 하드디스크에는 물리적인 섹터가 존재하지
minutemaid.tistory.com
Hybrid Mapping
hybrid mapping는 block-level mapping과 page-level mapping의 장점을 합친 것입니다. NAND Flash의 경우 데이터 블록과 로그 블록으로 나눌 수 이는데 이때 다수를 차지하는 데이터블록은 block-level mapping을 사용하며, 로그 블록은 page-level mapping을 사용합니다. 결국 hybrid mapping은 block-level mapping을 근간으로 하되, block level mapping의 문제를 해결하기 위해 소수의 로그블록을 page level mapping을 사용합니다.
hybrid mapping
- BAST
- FAST
- O-FAST
BAST (Block Associative Sector Translation)
BAST는 하이브리드 매핑의 초기 버전입니다. 주요 아이디어는 하나의 로그블록은 하나의 데이터블록을 전용으로 하는 1 to 1 매핑을 사용합니다. 이때 데이터를 데이터 블록에 업데이트하기 위해 Copy 동작을 하는 것이 아닌 업데이트된 데이터는 로그 블록에 기록합니다.

파일시스템으로부터 write이 LPN 4, 5, 4, 4의 순서대로 요청되면 LBN = 4 / 4 = 1에 해당하는 PBN(Physical Block Number) = 10의 Page Offset 0,1 에 LPN 4,5 가 순차적으로 쓰이게 됩니다. 그 후, LPN 4에 다시 write 요청이 들어오면 PBN = 10에 하나의 로그 블록이 할당되어 업데이트된 데이터를 쓰게 됩니다. 이 후 LPN 8, 9, 10, 11 에 대한 write 요청이 2번 반복 요청되면 또 다른 로그 블록을 할당하여 업데이트된 데이터를 쓰게 됩니다. 모든 로그 블록의 페이지가 overwrite되거나 다른 데이터 블록에 할당할 수 있는 로그 블록이 없는 경우 FTL은 로그블록에 대한 Merge 작업을 요청합니다.
Merge
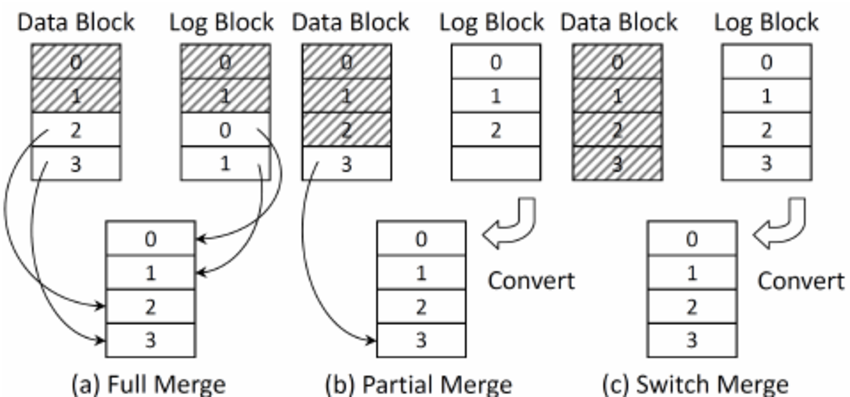
switch merge
데이터 블록에 업데이트 되어 invalid한 데이터가 존재하고 로그 블록에는 새로운 데이터가 있다고 한다면 데이터 블록과 로그 블록을 단순히 switch한 후에 데이터 블록에 있던 데이터를 삭제하여 free 블록으로 만들어줍니다. switch operation은 sequential write시 사용하게 되는 더욱 효율적인 operation이며, 이 과정에서는 한번의 erase 작업만을 요구합니다.
partial merge
데이터가 완전히 쓰여있지 않았을 경우 나머지 데이터를 데이터 블록으로부터 옮긴 뒤, merge를 완료해줄 수 있습니다.
아래 그림의 데이터 블록에서 0, 1, 2는 invalid data이며 3은 valid data인데, 이때 valid data를 로그 블록에 copy하면 데이터블록 모두가 invalid data가 되므로 데이터블록을 삭제한 후 기존의 로그블록을 데이터블록으로 바꿀 수 있습니다. 그 후 데이터 블록은 삭제하여 free block으로 만들어 줍니다. partial merge는 하나의 블록이 삭제되고 최대 페이지 개수 -1 개만큼 valid page copy가 발생할 수 있습니다.
Full merge
full merge의 경우에는 적어도 여분의 1개의 free log block이 필요합니다. 데이터 블록과 로그 블록에서 valid data를 free블록에 copy후 데이터 블록에 할당하게 되면 결국 원래의 데이터 블록과 로그블록은 삭제할 수 있습니다. Full merge는 최대 페이지 개수만큼 valid page copy가 발생할 수 있으며 2개의 블록이 삭제됩니다.
pros and cons
BAST의 경우 로그블록을 통해 임시적으로 업데이트하여 erase작업을 늦추기 때문에 block level mapping 보다는 성능이 좋으며, page level mapping보다는 메모리 사용이 적습니다. 하지만 random write의 경우 로그 블록의 효율이 떨어지는데, 이는 하나의 데이터 블록에 하나의 로그 블록을 할당하므로 merge 작업을 빈번하게 요구하기 때문입니다. 또한, 0, 4, 8, 12, 0, 4, 8, 12 (Np = 4)와 같은 write seqeuence의 경우 로그 블록의 일부분만 쓰여지므로 Log Block Thrashing 문제를 일으키는 단점이 있습니다.
FAST (Fully Associative Sector Translation)
FAST는 BAST의 단점을 극복하기 위해서 N to M으로 데이터블록과 로그블록을 매핑하는 방식을 사용합니다. NAND Flash에는 데이터 블록과 로그블록이 존재하는데, 앞서 BAST와 마찬가지로 데이터블록에는 block-level mapping을, 로그 블록은 page-level mapping을 사용합니다. 반면 로그 블록은 BAST와 달리 1개의 SW와 다수의 RW으로 나누는데, 이 때 sequential write이 발생 했을 때 switch merge를 최대한 하기 위해 (merge 작업 중 오버헤드가 가장 적으므로) SW를 1개 두게 됩니다.
SW
sequential write log block (SW)에 쓰기 작업이 수행되는 경우는 2가지 입니다.
1 ) LPN % NP == 0 (NP는 블록 내의 페이지수)
: 블록의 offset이 0이여서 업데이트가 첫번 째 페이지부터 일어난다는 뜻
2 ) LPN이 sequential 하고 offset이 다음 페이지일 때

다음 그림을 살펴 보겠습니다.
Case 1 : 4 % 4 = 0 이므로 SW에 write이 발생
Case 2.1 : 4 % 4 =0, 5 % 4 = 1 이므로 SW에 순차적으로 write 발생
Case 2.2 : 두번째 6이 RW에 write 됨
Case 2.3 : 4, 5는 SW에 세번째 5는 RW에 write 됨
RW

반면 RW 로그 블록는 victim을 라운드 로빈 방식으로 선정합니다. 로그 블록이 꽉 찬 경우 하나의 로그 블록을 victim으로 선정하는데, victim안의 페이지들은 하나의 전용 데이터 블록에서 업데이트 되어서 온 것이 아닙니다. 그렇기 때문에 보통 1번 이상의 full merge를 요구합니다.

라운드 로빈 방식으로 vicitm을 선정했다면 가장 최근 데이터인 LBN 0에 대해 full merge를 수행합니다.
FAST의 경우 SW와 RW을 구분함으로써 로그 블록의 utilization을 향상시켰습니다. 하지만, RW로그 블록의 경우 full scan을 요구하기 때문에 주소 변환 시간이 느리며, 데이터가 여러 LBN에서 오기 때문에 하나의 데이터를 reclaim하기 위한 오버헤드가 큽니다.
O-FAST (Optimized FAST)
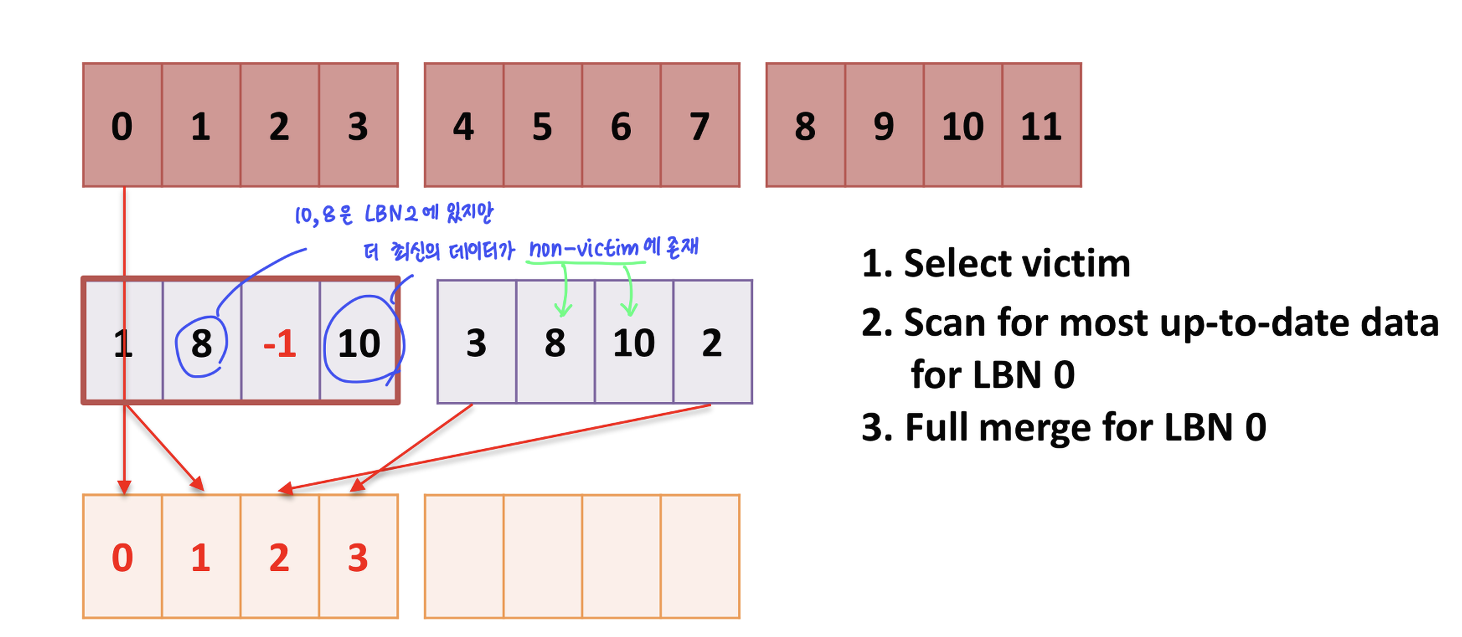
O-FAST는 개선된 FAST로, merge 작업을 최대한 늦추는 방식을 사용합니다. merge를 최대한 늦춘다는 것은 그만큼 erase작업도 늦출 수 있다는 것을 의미합니다. 즉 Lazy merge는 non-victim에 최신의 데이터 페이지가 존재하면 merge를 하지 않습니다. 아래 사진을 살퍄보면 8과 10은 LBN2에 존재하지만 더 최신의 데이터가 non-victim에 존재하기 때문에 merge를 하지 않기 때문에, 결국 erase 작업은 4번에서 2번으로 감소하게 되었습니다.
Performance
Pattern A : sequential write
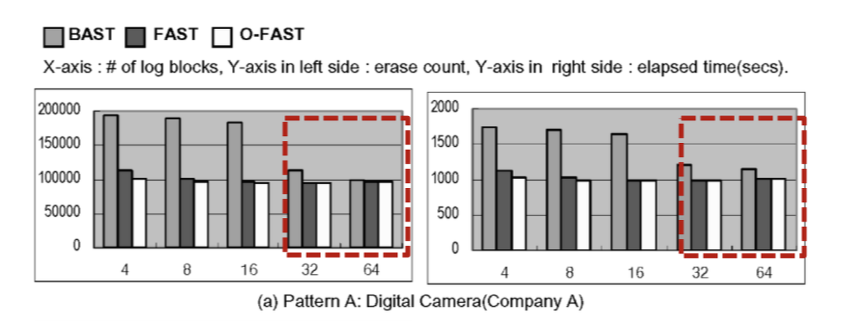
위 그림을 보면 x축은 로그 블록의 개수이며, y축은 erase count를 의미합니다. 패턴 A은 sequential write가 다수를 이루는 경우인데, 이때는 FAST와 O-FAST이 BAST보다 높은 것을 볼 수 있습니다.
Pattern B : random write

패턴 B의 경우 random write만 존재하는 케이스입니다. 이때 BAST는 random write workload에서 비어있는 페이지가 있는 블록도 계속해서 erase 작업을 엄청나게 수행하기 때문에 성능이 매우 좋지 않은 것을 볼 수 있으며, sequential write의 경우 블록이 다 찬 이후에 데이터 블록과 바꾸어 erase를 하므로 그 작업이 훨씬 적습니다.
'Storage' 카테고리의 다른 글
| DFTL (Demand-based FTL) (4) | 2022.04.10 |
|---|---|
| FTL (0) | 2022.01.09 |
| Data Deduplication (0) | 2021.12.21 |
| Wear Leveling (WL) (0) | 2021.11.27 |




댓글